")
")
")
")

Towards Critical Heritage in the wild: Analysing Discomfort through Collaborative Autoethnography
As we engaged in designing digital interventions for intercultural dialogues around public cultural heritage sites, we saw an opportunity to surface multiple interpretations and points of view of history and shine a critical lens on current societal issues. To do so, we present the results of a collaborative auto-ethnography of alternative tours accompanied by intercultural guides, to explore sensory and embodied engagements with cultural heritage sites in a southern European capital. By focusing on the differences in how we experienced the heritage sites, we analyse the duality of discomfort, a common concept in HCI, in that it can both be deployed as a resource for designing systems that can transform people’s understanding of history or it can be a hindrance for engagement, having an unequal effect on individuals.

Locality-aware subgraphs for inductive link prediction in knowledge graph
Recent methods for inductive reasoning on Knowledge Graphs (KGs) transform the link prediction problem into a graph classification task. They first extract a subgraph around each target link based on the -hop neighborhood of the target entities, encode the subgraphs using a Graph Neural Network (GNN), then learn a function that maps subgraph structural patterns to link existence. Although these methods have witnessed great successes, increasing often leads to an exponential expansion of the neighborhood, thereby degrading the GNN expressivity due to oversmoothing. In this paper, we formulate the subgraph extraction as a local clustering procedure that aims at sampling tightly-related subgraphs around the target links, based on a personalized PageRank (PPR) approach. Empirically, on three real-world KGs, we show that reasoning over subgraphs extracted by PPR-based local clustering can lead to a more accurate link prediction model than relying on neighbors within fixed hop distances. Furthermore, we investigate graph properties such as average clustering coefficient and node degree, and show that there is a relation between these and the performance of subgraph-based link prediction.

Fast re-OBJ: real-time object re-identification in rigid scenes
Re-identifying objects in a rigid scene across varying viewpoints (object Re-ID) is a challenging task, in particular when there are similar, even identical objects coexist in the same environment. Discriminative features play no doubt an essential role in addressing this challenge, while for practical deployment, real-time performance is another desired attribute. We therefore propose a novel framework, named Fast re-OBJ, that is able to improve both Re-ID accuracy and processing speed via tight coupling between the instance segmentation module and embedding generation module. The rich object encoding in the instance segmentation backbone is directly shared to the embedding generation module for training a more discriminative representation via a triplet network. Moreover, we create datasets with the segmentation outputs using real-time object detectors to train and evaluate our object embedding module. With extensive experiments, we prove that our proposed Fast re-OBJ improves the object Re-ID accuracy by 5% and the speed is faster compared to the state-of-the-art methods.

Writing with (Digital) Scissors: Designing a Text Editing Tool for Assisted Storytelling Using Crowd-Generated Content
Digital Storytelling can exploit numerous technologies and sources of information to support the creation, refinement and enhancement of a narrative. Research on text editing tools has created novel interactions that support authors in different stages of the creative process, such as the inclusion of crowd-generated content for writing. While these interactions have the potential to change workflows, integration of these in a way that is useful and matches users’ needs is unclear. In order to investigate the space of Assisted Storytelling, we designed and conducted a study to analyze how users write and edit a story about Cultural Heritage using an auxiliary source like Wikipedia. Through a diffractive analysis of stories, creative processes, and social and cultural contexts, we reflect and derive implications for design. These were applied to develop an AI-supported text editing tool using crowd-sourced content from Wikipedia and Wikidata.
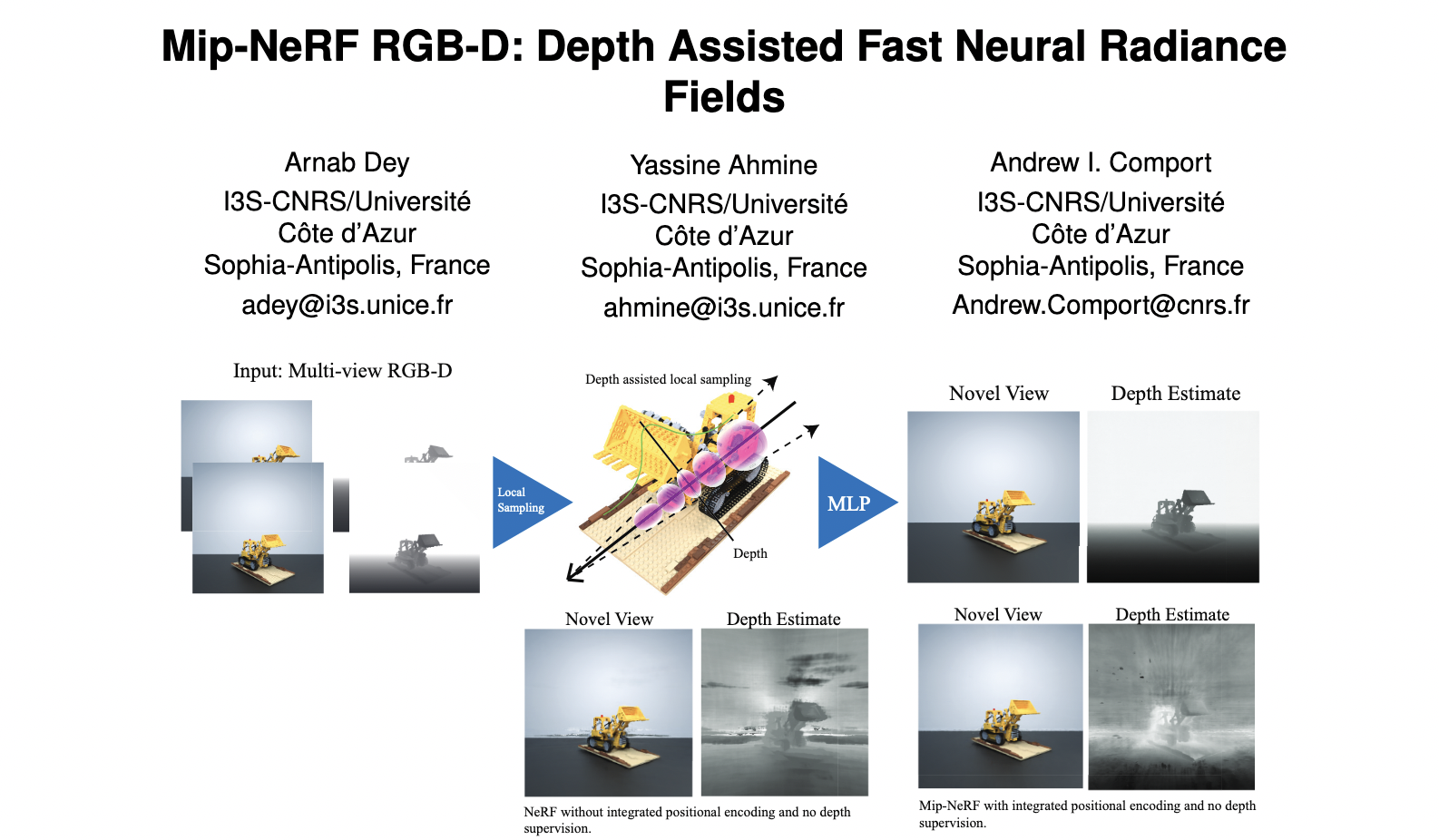
Mip-NeRF RGB-D: Depth Assisted Fast Neural Radiance Fields
Neural scene representations, such as Neural Radiance Fields (NeRF), are based on training a multilayer perceptron (MLP) using a set of color images with known poses. An increasing number of devices now produce RGB-D(color + depth) information, which has been shown to be very important for a wide range of tasks. Therefore, the aim of this paper is to investigate what improvements can be made to these promising implicit representations by incorporating depth information with the color images. In particular, the recently proposed Mip-NeRF approach, which uses conical frustums instead of rays for volume rendering, allows one to account for the varying area of a pixel with distance from the camera center. The proposed method additionally models depth uncertainty. This allows to address major limitations of NeRF-based approaches including improving the accuracy of geometry, reduced artifacts, faster training time, and shortened prediction time. Experiments are performed on well-known benchmark scenes, and comparisons show improved accuracy in scene geometry and photometric reconstruction,while reducing the training time by 3 - 5 times.

Spatial Commonsense Graph for Object Localisation in Partial Scenes
We solve object localisation in partial scenes, a new problem of estimating the unknown position of an object (e.g. where is the bag?) given a partial 3D scan of a scene. The proposed solution is based on a novel scene graph model, the Spatial Commonsense Graph (SCG), where objects are the nodes and edges define pairwise distances between them, enriched by concept nodes and relationships from a commonsense knowledge base. This allows SCG to better generalise its spatial inference to unknown 3D scenes. The SCG is used to estimate the unknown position of the target object in two steps: first, we feed the SCG into a novel Proximity Prediction Network, a graph neural network that uses attention to perform distance prediction between the node representing the target object and the nodes representing the observed objects in the SCG; second, we propose a Localisation Module based on circular intersection to estimate the object position using all the predicted pairwise distances in order to be independent of any reference system. We create a new dataset of partially reconstructed scenes to benchmark our method and baselines for object localisation in partial scenes, where our proposed method achieves the best localisation performance.

A Co-Design Method for Museums to Engage Migrant Communities with Cultural Heritage
This chapter presents an experimental method designed to engage migrant participants with local cultural heritage. The initiative was part of an exploratory field study conducted in the context of the European-funded project MEMEX, a research effort promoting the social wellbeing of communities at risk of exclusion through the narration and collection of memories and stories related to cultural heritage. To engage members of such communities with the topic of cultural heritage, we deployed a two-stage intervention: a five-day photo-challenge, where participants were asked to photograph sites that they felt connected to, and a four-hour co-design workshop in which they explored the photos they had captured and co-created stories around specific sites, linking them to their memories. This chapter reflects how this process can benefit designers, individuals, and organizations in the cultural sector in capturing and reflecting on cultural heritage, engaging communities at risk of exclusion while supporting scientific and societal impact.

People-Place Interactions: From Pictures and Stories to Places and Sense of Place
The emergence of a networked society generates transformations in the dynamic interactions of people impacting cultural and service systems. A location can provide different individual and collective meanings, perceptions, and experiences to different people. However, it is unclear how urban actors can collect, measure, and operationalise such place-based knowledge. Thus, this work addresses the Social-Design Modes theme from the IASDR community, rethinking how urban actors can interpret place-based knowledge from a given community. This research evaluates the potential of an exploratory method involving photo-based storytelling to unpack key factors associated with a place. Geographic Information Systems support the approach in order to transfer complex subjective experiences into simple and unique geographical representations. We provide empirical evidence of how this method operationalises individual and collective place-based knowledge through two study cases. This method merges design with the ‘social’ to respond to pressing social questions by urban actors. The methodological implications encountered through this process may act as guidelines to inform practitioners in related fields and other areas of knowledge.

Promoting Social Inclusion Around Cultural Heritage Through Collaborative Digital Storytelling
In this paper, we present a case study conducted in the context of the European-funded project MEMEX, a research effort promoting the social wellbeing of migrant communities at risk of exclusion, through the narration and collection of stories related to cultural heritage. The first step was to understand how migrant communities might connect with their host city’s heritage and how they potentially connect it with their own heritage. To achieve this, we deployed a field study with ten adult migrants (first- and second-generation Lisbon dwellers) articulated into two stages: (i) a five-day photo-challenge involving storytelling elucidated by pictures and short textual descriptions, followed by (ii) a four-hour audio recorded co-creation workshop, in which participants explored the material they had captured and co-created stories around specific sites, linking them to their memories. This method enabled the participants to express their opinions and experiences on social, cultural, and historical matters. By exploring their connections with the places they inhabit through their own, personal narratives and sharing these with their peers, the participants activated a discussion process exploring the role of storytellers. This case study focuses on the lessons learned and the limitations of the practical work carried out.

Lights: Light Specularity Dataset For Specular Detection In Multi-View
Specular highlights are commonplace in images, however, methods for detecting them and removing the phenomenon are particularly challenging. A reason for this is the difficulty in creating a dataset for training or evaluation, as in the real world, we lack the necessary control over the environment. Therefore, we propose a novel physically-based rendered LIGHT Specularity (LIGHTS) Dataset for the evaluation of the specular highlight detection task. Our dataset consists of 18 high-quality architectural scenes, where each scene is rendered with multiple views. In total, the dataset contains 2, 603 views with an average of 145 views per scene. Additionally, we propose a simple aggregation based method for specular highlight detection that outperforms prior work by 3.6% in two orders of magnitude less time on our dataset.

Collecting Qualitative Data During COVID-19
The current pandemic situation leads researchers to reflect on conducting qualitative research, completely changing how they conduct participatory research. As it became clear that the pandemic would last many months, researchers started to redesign their planned research in digital spaces through social media channels and participatory online tools. From communicating with participants over Zoom (or other similar applications) to sharing information on exclusive online groups, digital platforms have become, for many, the only way to work, learn, or be entertained. This situation offered a significant opportunity to think creatively about research engagement and reflect on which aspects truly require researchers to be “on the ground” to conduct face-to-face participatory sessions to gather qualitative data. Qualitative researchers must use this opportunity to reflect while using digital tools for distance research. This paper is inspired by the work the authors are conducting in MEMEX – a European-funded project promoting social inclusion by developing collaborative storytelling tools related to cultural heritage and at the same time facilitating encounters and interactions between communities at risk of social exclusion. Thus, the work here presented reflects on the digital tools and techniques to collect qualitative data when the researchers cannot meet the participants face-to-face due to pandemics safety measures or other restrictions.

Impalpable Narratives: How to capture intangible cultural heritage of migrant communities
According to UNESCO, Intangible Cultural Heritage (ICH) refers to the acts, expressions, and understandings and the associated objects and environments embedded within the ideas and customs of communities and individuals. Sometimes these facets are passed down through generations, but they can also be lost as people’s surrounding circumstances change. This paper investigates how Digital Storytelling (DS) can explore and enable discussions surrounding the various interpretations of ICH, particularly in communities at risk of social exclusion. The authors outline a DS field study, which engaged with ICH notions with first and second-generation migrant participants in Portugal. This process’s objectives were to observe what kinds of stories these methods could elicit and if some ICH form would feature in them. The outcomes were then analyzed to understand if and what sort of ICH is highlighted and how it connects to their present surroundings. These insights were used to inform the requirements of a new interactive DS platform for the authoring and viewing of stories that engage with the subject of ICH.

Digital Storytelling and lifelong learning education in informal contexts: the MEMEX project
This contribution intends to present the design, methodology and first results of MEMEX, a 3-year project (2019-2022) funded by the European programme Horizon2020, aimed at promoting social cohesion through collaborative, heritage-related tools that provide inclusive access to tangible and intangible cultural heritage (CH) and, at the same time, facilitates encounters, discussions and interactions between communities at risk of social exclusion. Cultural participation is conceived as a way to engage communities in lifelong learning processes taking place in informal contexts, aiming at promoting social inclusion and cohesion. To achieve these goals, MEMEX uses innovative ICT tools that provide a new paradigm for interaction with heritage through Digital Storytelling (DS), weaving heritage-related memories and experiences of the participating communities with the physical places/objects that surround them. The project encompasses the ICT tools and the use of DS in the framework of Audience Development (AD), defined as a strategic and dynamic process enabling cultural organisations to place audiences at the centre of their action. The use of DS applied to CH is highly related to lifelong learning processes, since it provides knowledge, understanding, awareness, engagement and interest, enjoyment and creativity. The evaluation of a number of DS produced by migrant women participating in a MEMEX pilot project in Barcelona confirms the validity and soundness of the methodology and the power of DS to engage in cultural experiences.

Machine Learning for Cultural Heritage: A Survey
The application of Machine Learning (ML) to Cultural Heritage (CH) has evolved since basic statistical ap- proaches such as Linear Regression to complex Deep Learning models. The question remains how much of this actively improves on the underlying algorithm versus using it within a ‘black box’ setting. We sur- vey across ML and CH literature to identify the theoretical changes which contribute to the algorithm and in turn them suitable for CH applications. Alternatively, and most commonly, when there are no changes, we review the CH applications, features and pre/post-processing which make the algorithm suitable for its use. We analyse the dominant divides within ML, Supervised, Semi-supervised and Unsupervised, and reflect on a variety of algorithms that have been extensively used. From such an analysis, we give a crit- ical look at the use of ML in CH and consider why CH has only limited adoption of ML.